
June 22, 2016
New tool for virtual and augmented reality uses ‘deep learning’
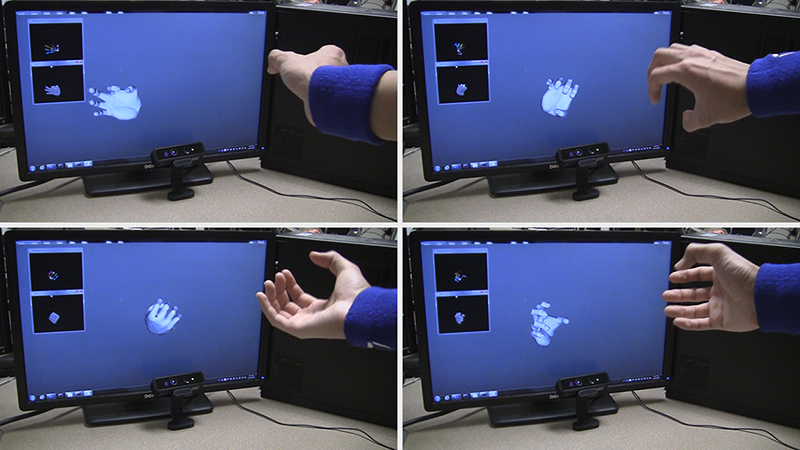 This series of photos shows the use of a new system, called DeepHand, developed by researchers in Purdue University’s C Design Lab. It is capable of “deep learning” to understand the hand’s nearly endless complexity of joint angles and contortions, an advance that will be needed for future systems that allow people to interact with virtual environments in virtual and augmented reality. (Purdue University image/C Design Lab)
Download image
This series of photos shows the use of a new system, called DeepHand, developed by researchers in Purdue University’s C Design Lab. It is capable of “deep learning” to understand the hand’s nearly endless complexity of joint angles and contortions, an advance that will be needed for future systems that allow people to interact with virtual environments in virtual and augmented reality. (Purdue University image/C Design Lab)
Download image
WEST LAFAYETTE, Ind. – Future systems that allow people to interact with virtual environments will require computers to interpret the human hand’s nearly endless variety and complexity of changing motions and joint angles.
In virtual and augmented reality, the user wears a headset that displays the virtual environment as video and images. Whereas augmented reality allows the user to see the real world as well as the virtual world and to interact with both, virtual reality completely immerses the user in the artificial environment.
“In both cases, these systems must be able to see and interpret what the user’s hands are doing,” said Karthik Ramani, Purdue University’s Donald W. Feddersen Professor of Mechanical Engineering and director of the C Design Lab. “If your hands can’t interact with the virtual world, you can’t do anything. That’s why the hands are so important.”
A new system, DeepHand, uses a “convolutional neural network” that mimics the human brain and is capable of “deep learning” to understand the hand’s nearly endless complexity of joint angles and contortions.
“We figure out where your hands are and where your fingers are and all the motions of the hands and fingers in real time,” Ramani said.
A research paper about DeepHand will be presented during CVPR 2016, a computer vision conference in Las Vegas from Sunday (June 26 )to July 1 (http://cvpr2016.thecvf.com/).
DeepHand uses a depth-sensing camera to capture the user’s hand, and specialized algorithms then interpret hand motions. (A YouTube video is available at https://youtu.be/ScXCqC2SNNQ)
“It’s called a spatial user interface because you are interfacing with the computer in space instead of on a touch screen or keyboard,” Ramani said. “Say the user wants to pick up items from a virtual desktop, drive a virtual car or produce virtual pottery. The hands are obviously key.”
The research paper was authored by doctoral students Ayan Sinha and Chiho Choi and Ramani. Information about the paper is available on the C Design Lab Web site at https://engineering.purdue.edu/cdesign/wp/deephand-robust-hand-pose-estimation/. The Purdue C Design Lab, with the support of the National Science Foundation, along with Facebook and Oculus, also co-sponsored a conference workshop (http://www.iis.ee.ic.ac.uk/dtang/hands2016/#home).
The researchers “trained” DeepHand with a database of 2.5 million hand poses and configurations. The positions of finger joints are assigned specific “feature vectors” that can be quickly retrieved.
“We identify key angles in the hand, and we look at how these angles change, and these configurations are represented by a set of numbers,” Sinha said.
Then, from the database the system selects the ones that best fit what the camera sees.
“The idea is similar to the Netflix algorithm, which is able to select recommended movies for specific customers based on a record of previous movies purchased by that customer,” Ramani said.
DeepHand selects “spatial nearest neighbors” that best fit hand positions picked up by the camera. Although training the system requires a large computing power, once the system has been trained it can run on a standard computer.
The research has been supported in part by the National Science Foundation and Purdue’s School of Mechanical Engineering.
Writer: Emil Venere, 765-494-3470, venere@purdue.edu
Source: Karthik Ramani, 765-494-5725, ramani@purdue.edu
Note to Journalists: An electronic copy of the research paper is available by contacting Emil Venere, 765-494-4709, venere@purdue.edu. Video is available on Google Drive at https://goo.gl/a9vQ8h. For additional video, contact Erin Easterling, digital producer in Purdue's College of Engineering, easterling@purdue.edu, 765-496-3388.
ABSTRACT
DeepHand: Robust Hand Pose Estimation by Completing a Matrix Imputed with Deep Features
Ayan Sinha∗ Chiho Choi∗ Karthik Ramani Purdue University
1C Design Lab, School of Mechanical Engineering, Purdue University
We propose DeepHand to estimate the 3D pose of a hand using depth data from commercial 3D sensors. We discriminatively train convolutional neural networks to output a low dimensional activation feature given a depth map. This activation feature vector is representative of the global or local joint angle parameters of a hand pose. We efficiently identify ’spatial’ nearest neighbors to the activation feature, from a database of features corresponding to synthetic depth maps, and store some ’temporal’ neighbors from previous frames. Our matrix completion algorithm uses these ’spatio-temporal’ activation features and the corresponding known pose parameter values to estimate the unknown pose parameters of the input feature vector. Our database of activation features supplements large viewpoint coverage and our hierarchical estimation of pose parameters is robust to occlusions. We show that our approach compares favorably to state-of-the-art methods while achieving real-time performance (≈ 32 FPS) on a standard computer. A technically-oriented YouTube video is available at and https://youtu.be/oSCWMvPdbBg.
