Frequently Asked Questions
Service-Specific FAQs
Project-Related FAQs
General FAQ
Why am I getting an error when uploading files using SFTP even though the upload completes?
If, when uploading files with an SFTP client, you see an error like the following, your upload actually succeeded, but you have a client setting enabled that’s causing the error:
Upload of file ‘filename’ was successful, but error occurred while setting the permissions and/or timestamp.
This is most common for users of the popular WinSCP SFTP client, since its default settings are to try to set timestamps on the remote server when uploading files, which will often cause the above error on Purdue IT servers. You’ll need to disable any settings that attempt to change permissions or preserve timestamps, either application-wide or for the SFTP profiles you have saved for Purdue IT web servers. For example, to disable these settings application-wide in WinSCP:
- Click the
Toolsmenu/button and pick Preferences - Click on the
Transferoption in the left column and make sure Default is selected on the right - Click
Edit - Un-check
Preserve timestampon the right. Also make sureSet permissionsisn’t checked. - Click
OK, then clickOKagain (you have to clickOKin each open window or the change won’t be saved). - Repeat steps 3-5 for each other type (Text, Binary, etc.)
- Test your upload again. If you still get an error, you may need to re-create your saved SFTP session(s) that are impacted or adjust each individually to match the above.
This issue occurs in shared sites like this because you often won’t be the owner (permissions-wise) of everything you’re updating. Even though you have permission to modify a file, that doesn’t grant permission to modify the file permissions or timestamp.
Why are embedded Google Maps no longer working on my site?
In July of 2018, Google made a change to the Google Maps API, transitioning it from a free to a paid service. While anyone may continue using the Google Maps website for free, access to the back-end API, which many popular WordPress plugins and other web libraries use to display maps, is no longer free. You’ll know if you’re using the API rather than regular, free Maps access if you’ve had to insert an “API Key” from your Google account into your web site configuration. Unfortunately there is nothing Web Services can do about this situation.
Those who wish to continue using the Google Maps API must register a credit card with their Google API account in order to continue using the service. Typically, colleges and departments will want to discuss this with their business offices. As of November 2018, once a credit card has been entered, you will get a free quota of API requests each month to go through before you are charged. To the best of our understanding, you can optionally set limits to prevent your card from ever being charged or to keep it from being charged over a certain amount, but keep in mind that your site’s Maps features will stop working after that point. The free quota is supposed to be sufficient for “low traffic” sites.
You can learn more about the Google Maps API and their policies at Google’s FAQ site. If you are having any issues with Google Maps, the Google Maps API, billing, or anything related to your Google account, you will need to contact Google Support directly.
While Web Services cannot make any recommendations about free or lower cost alternatives, the following options exist and may meet your needs:
- If you only want to display one map, such as your office location, follow Google’s instructions to generate an embed code and use that instead.
- Linking directly to a specific location (or dropped pin) at maps.google.com does not use the API, and is free. Google provides documentation about generating Google Maps URLs based on street address or latitude/longitude.
- Other mapping services, such as OpenStreetMap (OpenStreetMap Documentation), could be a good alternative where it’s possible to use them.
What are the differences between absolute and relative URLs?
Absolute URLs contain the whole URL. They always work, but need to be updated whenever your site’s path changes, which includes between Development, QA, and Production, so should almost never be used in a multi-tier environment. Some examples:
https://www.purdue.edu/example-site/css/style.csscan be referenced like this by any page or site*.https://www.purdue.edu/example-site/page.htmlworks as a link from any page on any site.- From any page you can reference
https://www.purdue.edu/example-site/images/header.pngdirectly using an absolute URL.
*Note: May be limited by the Access-Control-Allow-Origin header.
Site-Relative URLs contain only the path to the resource from the root of your site, represented by the leading /. These are the best to use when the page referencing the resource varies, which is very often the case, but need to be updated if your site ever moves to another location. Some examples:
/example-site/css/style.csscan be referenced like this by any page in thehttps://www.purdue.edusite. It would be interpreted ashttps://www.purdue.edu/example-site/css/style.css./example-site/page.htmlworks as a link from any page within thehttps://www.purdue.edu/site. It would be interpreted ashttps://www.purdue.edu/example-site/page.html.- From any page in the
https://www.purdue.edu/site you can reference/example-site/images/header.png. It would be interpreted ashttps://www.purdue.edu/example-site/images/header.png.
Relative URLs contain that path from the current location to the required resource. They are easiest to use when you have something like a CMS managing links, and allow your site to be fully portable, working wherever it is moved. Some examples:
- You can reference the same
style.cssused in previous examples as../css/style.cssfrom withinhttps://www.purdue.edu/example-site/about/contact.html, where it would be interpreted ashttps://www.purdue.edu/example-site/css/style.css. Other pages in theaboutdirectory could use the same relative link, as could pages in other directories at the same depth as theaboutdirectory. page.htmlworks from any other page in the same directory aspage.html. Using the previous examples, ifpage.htmlis in the root ofhttps://www.purdue.edu/example-site/, that would mean the relative link would be interpreted ashttps://www.purdue.edu/example-site/page.html. If you wanted to link back to page.html fromhttps://www.purdue.edu/example-site/resources/another-page.html, you could use../page.htmlinstead, since the relative link would still be interpreted ashttps://www.purdue.edu/example-site/page.html.- From a page with a URL like
https://www.purdue.edu/example-site/deeply/nested/page.html, you can reference the example header image as../../images/header.png. Within that context, the URL forheader.pngis stillhttps://www.purdue.edu/example-site/images/header.png.
You’ll notice many of those make use of the .. directory operator. What that does is tell your browser to go up one level in the directory tree, like the “arrow up” button does in Windows Explorer. This operator can be used to go up as far as the root level of your site.
Why does my site work on campus but is broken when viewed off-campus?
Your site may work on campus but not work off-campus for a few reasons:
- You’re viewing the non-Production (Development or QA) version of your site instead of the Production version of your site. Only Production sites are accessible from off-campus networks.
- You’re viewing your Production site while off-campus, but your site’s code is referencing a non-Production site for some or all elements or links. This is a common issue for sites that use absolute URLs for links and references. See this frequently asked question for how to fix this.
- All or part of your site has directory security placed on it that prevents access from off-campus. Make sure to place shared resources like images and style sheets in non-protected directories. If the applied directory security is no longer needed, let Web Services know and that can be changed.
Access to non-Production (Development and QA) sites is blocked from off-campus unless there is a very good reason for an exception. This prevents web crawlers from indexing non-Production sites, which keeps your non-Production sites from showing up in search results accidentally. This also protects your pre-Production code that has yet to go through a security review.
How can I find and fix missing elements on my web pages?
Sometimes, when you open a web page, you’ll notice missing elements like broken images, missing styles, the wrong fonts, etc. You may also notice that this only occurs on certain devices or in certain situations. The following is a list of the most likely causes and how to fix them.
- If the page looks fine in Development, but elements are missing in QA and/or Production:
- Check to make sure you’ve fully deployed your site, or if when you deployed your site there were errors.
- If you’ve only deployed the HTML, PHP, or ASPX files, but didn’t deploy the CSS, images, or JavaScript files, those elements will be missing.
- If the page works correctly when you’re on campus, but elements are missing when viewed from an off-campus connection without a VPN:
- Your page is most likely referencing images, styles, etc. from Development or QA, and access to Development and QA is generally restricted to campus IPs.
- Update your site code to reference these elements using relative or site-relative URLs. For example, instead of
<link href="https://dev.www.purdue.edu/example-site/css/style.css" rel="stylesheet">, use<link href="/example-site/css/style.css" rel="stylesheet">(a site-relative URL) instead. - For PHP, ASP.NET, and other sites using active server-side code, you can also have your site code check the TIER environment variable to select the correct settings for Development, QA, or Production as the case may be.
- For Cascade sites, these issues are normally corrected automatically unless there are static references defined in the templates used for pages. Check with Cascade support if you’re not sure how to fix these references.
- WordPress sites will make these corrections automatically where they can, but you may need to inspect your site’s child theme, if used, for direct references and convert them either to relative or site-relative links (see above) or by using a built-in WordPress function to determine the absolute site path.
- If the page doesn’t display correctly anywhere:
- The referenced elements may not exist. Check to make sure you’ve published them or uploaded them to the server.
- You may have spelled something wrong or included a typo in the path to the referenced element. Fix your errors and the element should load correctly.
- If your site has a temporary URL, like
https://new.example.purdue.edu, the temporary URL may not be in the SSL certificate, and your browser is refusing to load elements that have SSL issues.- To temporarily work around this so you can test, copy and paste the temporary URL into your browser’s address bar and press enter or return. If you see an SSL warning about a name mis-match, the certificate shown is for your site’s real URL, and you’ve double-checked that you’ve entered your temporary URL correctly, tell your browser to trust the SSL certificate anyway, then resume testing and the element should load normally. If any of that is not true, stop and contact Web Services for help.
- Alternatively, ask Web Services to update your temporary URL to have a working SSL certificate. This may take a few days to set up.
Something useful when diagnosing missing page elements is your browser’s Web Inspector or Developer Tools view:
- You can access these tools on a Windows or Linux-based web browser by pressing F12. On Macs, press Command+Option+i instead. You may also find a clickable link in your browser’s menus, depending on the browser and configured options.
- One useful tab for this kind of work is the Network tab. You may need to click a button to refresh the broken page once you’re on the Network tab to make it show anything. Some browsers will show a Status column on the left, and you’ll be looking for elements that don’t show a status or show an error status, like 403 or 404. Other browsers will use color to designate issues (usually red).
- Another useful tab is the Console, which shows all errors and warnings your browser encounters when loading a page. These often tell you in plain language what’s wrong, and can be useful in finding and fixing problems.
- Finally, some browsers have a Sources tab that shows the elements of your page as a directory tree view, with the URLs where page elements come from at the left-most level. If you’re on a Production page and see a non-Production URL in this tree view, you know some elements are coming from the wrong site whether they’re working (because you’re on campus or using a VPN) or not!
How do I ensure my links work in Development, QA, and Production?
When linking to other pages, you want to make sure your links work regardless of whether you’re viewing the Development, QA, or Production version of your site so you’re able to test. It’s also important that your Production site doesn’t accidentally link to a Development or QA site on accident. Fortunately, it’s very easy to avoid this mistake:
Cascade Sites
Cascade can automatically manage your links for you. To set this up, when editing your site in Cascade, click the Manage Site button in the toolbar (you may need to expand your browser window before it will show up), then click on Site Settings:

For most sites, you’ll want to enable Relative Links in the Link Rewriting section (you’ll need to scroll down in the site settings to see it). This will apply site-wide except for pages where you need a different setting. You’ll need to re-publish and re-deploy your whole site after changing this option.

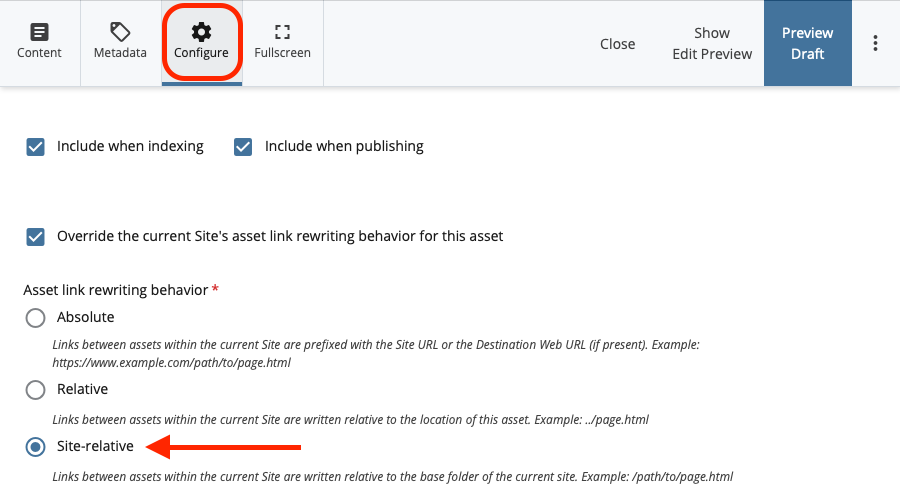
For some pages, especially 404 pages or other assets that might be referenced by multiple paths, you’ll need to use Site-relative links. You can of course just set Site-relative links globally too, though doing so can make operations like renaming your site more difficult. To change an individual asset’s link rewriting, while editing the asset click on Configure at the top of the editor, then find the Link Rewriting section near the top. You’ll need to re-publish and re-deploy any assets where you change this setting.
WordPress Sites
WordPress only uses absolute links. You can manually specify relative and site-relative links when adding a link to a page, but otherwise WordPress manages everything as absolute links in the background. Not to worry, though, because Deploy will automatically change all absolute links to use the correct URLs as a site is deployed.
That said, if you include hard-coded links in your site’s theme, child theme, or custom plugins, these won’t be automatically updated by Deploy. You’ll usually want to use site-relative links in these situations, but in the case of a PHP file, you might also be able to use a WordPress function to determine your site’s current URL.
Everything Else
In general, it is easiest to use site-relative links when you’re hand-coding a web page.
Why do I have (DATA) on some of my deploy labels?
The (DATA) directory is a useful place to store files that control your site, but should not be publicly readable. One of the most common uses is storing a list of users allowed to access a site.